MySQL 索引分类、最左匹配与失效场景:面试必考点梳理
索引类似与书籍的目录,从全表扫描改成了根据索引查找,提高了查找效率
如果查询的时候,没有用到索引就会全表扫描,这时候查询的时间复杂度是 O(N)
如果用到了索引,那么查询的时候,可以基于二分查找算法,通过索引快速定位到目标数据,MySQL 索引的数据结构一般是 B+ 树,其搜索复杂度为 O(logdN),其中 d 表示节点允许的最大子节点个数。
讲讲索引的分类是什么?
MySQL的索引可以分为4类:
按数据结构:B+Tree索引、Hash索引、Full-text索引
按物理存储:聚簇索引(主键索引)、辅助索引(二级索引)
按字段特性:主键索引、唯一索引、前缀索引、普通索引
按字段个数:单列索引、复合索引(又叫联合索引)
按数据结构分
分为B+Tree索引、Hash索引、Full-text索引
B+Tree索引
. 对于 InnoDB 的聚簇索引 (Clustered Index)
非叶子节点:存储索引键值(比如主键ID)和指向下一层节点的指针。
叶子节点:存储完整的行数据(所有列的值)。
一句话:找到叶子节点,就找到了整行数据。
对于 InnoDB 的二级索引 (Secondary Index)
非叶子节点:存储索引键值(比如
name列的值)和指向下一层节点的指针。
叶子节点:存储索引键值(
name的值)和对应的主键值(不是完整行数据)。
一句话:找到叶子节点,只得到主键值,还需要回表查询聚簇索引才能拿到完整行数据。
Hash索引底层是Hash表也就是一个一个 键值对 ,在查找单个元素很快,接近O(1),并且只能做精确查找
Full-text索底层是倒排索引,使用于搜索引擎,根据词去定位文档,根据值去定位id。
后面两个索引都属于二级索引也就是辅助索引
这里介绍一下什么是倒排索引,倒排索引就是“根据关键词(词)查找其所在位置(文档ID/行)”的映射表,与“根据文档找词”的正排相反。
| 特性 | Hash 索引 | Full-Text 索引 |
|---|---|---|
| 核心设计 | 精确匹配(等值查询) | 自然语言搜索(关键词匹配) |
| 典型查询 | WHERE col = "abc" | WHERE MATCH(col) AGAINST("关键词") |
| 不支持 | 范围查询(>、<、BETWEEN)模糊查询( LIKE) | 普通的 = 或 LIKE 查询(效率极低) |
| 底层算法 | 哈希表 | 倒排索引(Inverted Index) |
| 主要用途 | 高性能的简单键值查询 | 搜索引擎风格的内容搜索 |
| 引擎支持 | 主要是 Memory 引擎 | 仅 InnoDB、MyISAM 引擎 |
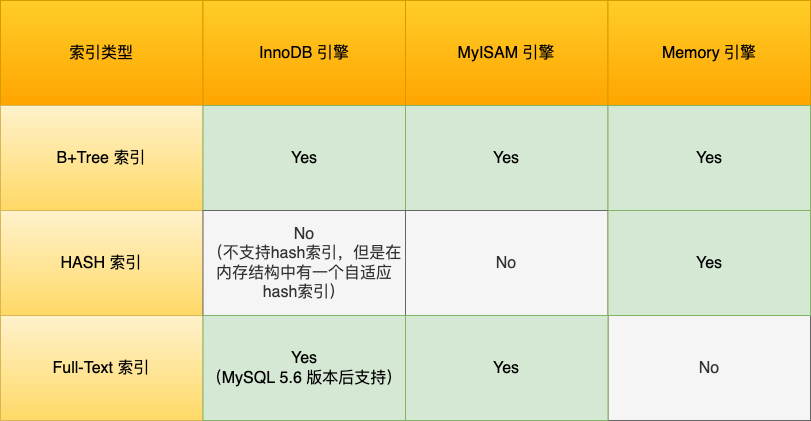
默认引擎InnoDB在建表时会根据不同场景来选择索引键
1.在建表时如果有主键,那么会选择主键来作为聚簇索引
2.如果没有主键,会选择第一个不为NULL值的唯一列来作为聚簇索引
3.如果两个都没有,InnoDB会创建一个默认的自增id来作为聚簇索引
注意:创建的主键索引和二级索引默认使用的是 B+Tree 索引。
按物理存储分
分为聚簇索引(主键索引)、辅助索引(二级索引)
这里的物理存储是指存储数据的方式:
主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
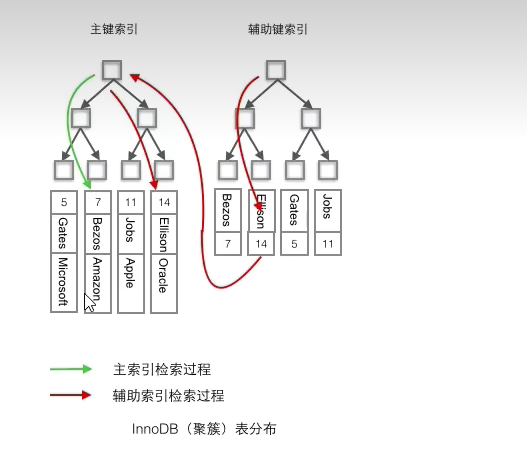
在查询时使用了二级索引,如果查询的数据能在二级索引里查询的到,那么就不需要回表,这个过程就是覆盖索引。如果查询的数据不在二级索引里,就会先检索二级索引,找到对应的叶子节点,获取到主键值后,然后再检索主键索引,就能查询到数据了,这个过程就是回表。
按字段特性分
分为主键索引、唯一索引、前缀索引、普通索引
故名思意就是有主键的索引,唯一列需要的索引,只用前缀就可以建立的索引、普通没有特点但需要快速查询的列需要的索引
主键索引创建(PRIMARY KEY):
主键索引就是建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只有一个主键索引,索引列的值不允许有空值。
CREATE TABLE table_name ( .... PRIMARY KEY (index_column_1) USING BTREE );
唯一索引创建(UNIQUE KEY)
唯一索引建立在 UNIQUE 字段上的索引,一张表可以有多个唯一索引,索引列的值必须唯一,但是允许有空值。
CREATE TABLE table_name ( .... UNIQUE KEY(index_column_1,index_column_2,...) );
建表后,如果要创建唯一索引,可以使用这面这条 命令 :
CREATE UNIQUE INDEX index_name ON table_name(index_column_1,index_column_2,...);
普通索引
普通索引就是建立在普通字段上的索引,既不要求字段为主键,也不要求字段为 UNIQUE。
在创建表时,创建普通索引的方式如下:
CREATE TABLE table_name ( .... INDEX(index_column_1,index_column_2,...) );
建表后,如果要创建普通索引,可以使用这面这条命令:
CREATE INDEX index_name ON table_name(index_column_1,index_column_2,...);
前缀索引
前缀索引是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。
使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
在创建表时,创建前缀索引的方式如下:
CREATE TABLE table_name( column_list, INDEX(column_name(length)) );
建表后,如果要创建前缀索引,可以使用这面这条命令:
CREATE INDEX index_name ON table_name(column_name(length));
这里可以举例说明 -- 你的查询 SELECT * FROM articles WHERE content = 'apple';
数据库使用前缀索引的查找步骤:
计算查询值的前缀:取
'apple'的前 N 个字符 →'app'(假设前缀长度是3)
在索引中找
'app':定位到索引中'app'这个键
拿到对应的主键列表:上面例子中
'app'对应 ID 1, 2, 3
回表查完整数据:去聚簇索引拿 ID 1, 2, 3 的完整行
再过滤一遍:只返回
content完整值 真正等于'apple'的那一行(ID 1)
按字段个数分类
分为单列索引、联合索引(复合索引)。
建立在单列上的索引称为单列索引,比如主键索引;
建立在多列上的索引称为联合索引;
通过将多个字段组合成一个索引,该索引就被称为联合索引。
比如,将商品表中的 product_no 和 name 字段组合成联合索引(product_no, name),创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);
这里重点讲解一下复合索引,底层在叶子节点是双向链表
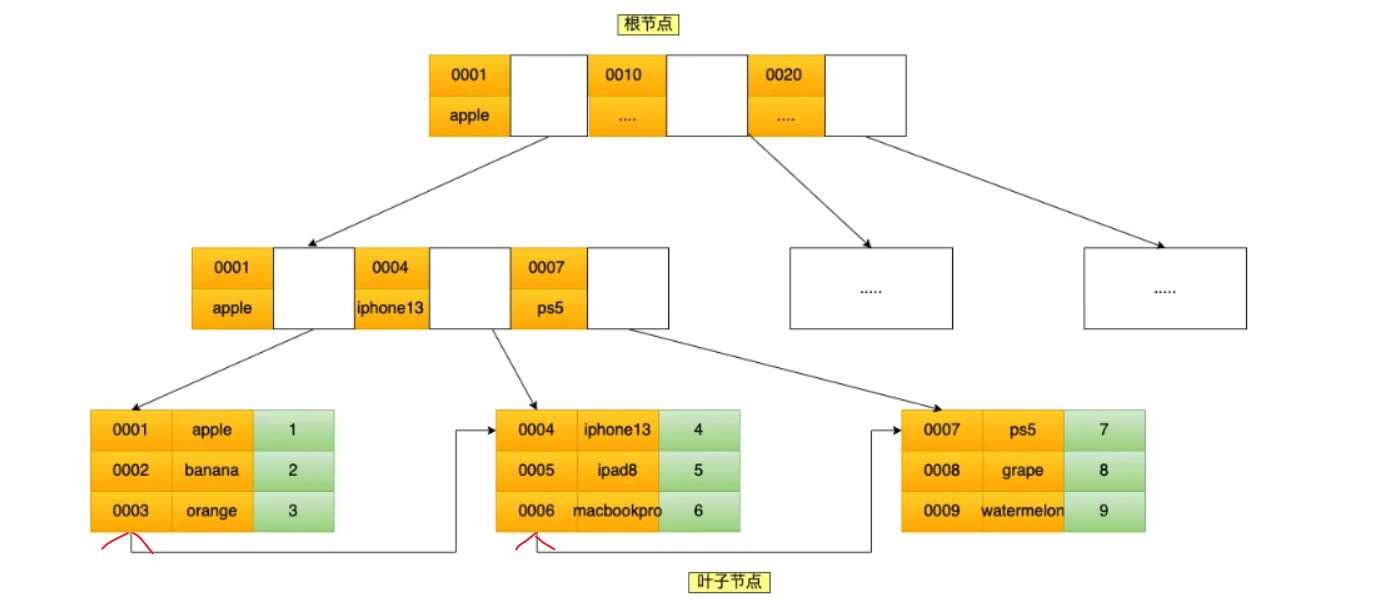
在查找时可以看到,联合索引的非叶子节点用两个字段的值作为 B+Tree 的 key 值。当在联合索引查询数据时,先按 product_no 字段比较,在 product_no 相同的情况下再按 name 字段比较。
也就是说,联合索引查询的 B+Tree 是先按 product_no 进行排序,然后再 product_no 相同的情况再按 name 字段排序。
最左匹配原则
即先按照索引最左边的列进行排序,再按后面的排序,如果不遵循这个原则,就无法使用联合索引
比如,如果创建了一个 (a, b, c) 联合索引,如果查询条件是以下这几种,就可以匹配上联合索引:
where a=1;
where a=1 and b=2 and c=3;
where a=1 and b=2;
where b=2 and a=1 and c=3;
需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。
但是,如果查询条件是以下这几种,因为不符合最左匹配原则,所以就无法匹配上联合索引,联合索引就会失效:
where b=2;
where c=3;
where b=2 and c=3;
上面这些查询条件之所以会失效,是因为(a, b, c) 联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是无法利用到索引的。
还有一种是通过a,b,c三列建造的索引,where a = 1,b = 2,c = 3,d = 4时只有前面三个能用
a=1 → 用到索引(最左前缀,精准定位)
b=2 → 用到索引(等值查询,在 a 相同的基础上 b 有序)
c=3 → 用到索引(等值查询,在 a、b 都相同的基础上 c 有序)
d=4 → 用不到索引,因为索引里根本没有 d 这一列
失效情况
联合索引的最左匹配原则在从左到右的查询如果遇到了范围查询,在范围查询之后就会停止。
这里举例说明一下
假设联合索引是 (a, b, c, d),查询条件是:
WHERE a = 1 AND b > 2 AND c = 3 AND d = 4
此时的匹配情况是:
a = 1 → 用到索引(等值,精准定位)
b > 2 → 用到索引(范围查询,走索引确定范围的起止边界)
c = 3 → 用不到索引的 B+Tree 有序性,因为 b 是范围查询,b 相同值的内部 c 才有序,跨 b 范围后 c 就无序了
d = 4 → 同样用不到
结论:a 和 b 两个字段用到了索引,c 和 d 没用到。b = 2这种条件才能保证后续有序,再b > 2就不一定有序了
联合索引 (a, b, c, d) 的排序逻辑是:
先按 a 排序
a 相同的情况下,按 b 排序
b 相同的情况下,按 c 排序
c 相同的情况下,按 d 排序
举个例子:
(a=1, b=3, c=1)
(a=1, b=3, c=5)
(a=1, b=4, c=2) <-- 注意这里,b值变了
(a=1, b=4, c=8)
(a=1, b=5, c=3) <-- c=3 在这里
