Token 消耗降低 90%:OpenClaw 降本增效实战指南
前几天,飞书群里有朋友问我:“为什么你的 OpenClaw 机器人响应这么快?我们的又慢又卡,动不动就卡死。”
说实话,我之前也被这个问题困扰过。
用 OpenClaw 搭建 AI 助手时,你肯定遇到过这些情况:随便聊几轮就提示达到使用限制,每次提问都要等好几秒甚至十几秒,严重的时候直接卡死。更要命的是,看着 API 账单一路飙升,心里总觉得不值——明明只是想让它回忆一下之前的对话,为什么要塞那么多无关内容进去?
问题根源:上下文爆炸
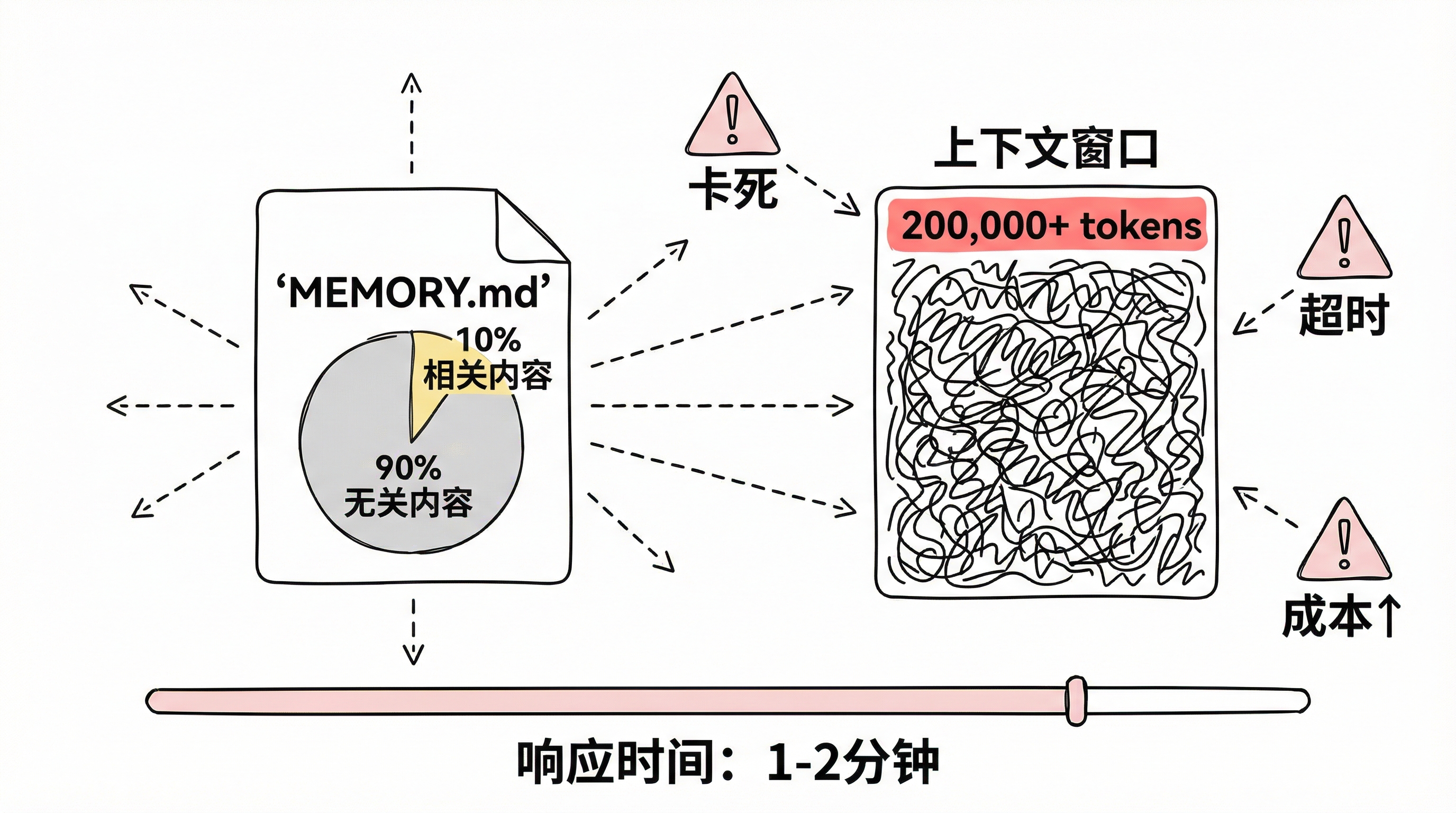
传统的记忆系统会把整个 MEMORY.md 文件直接塞进上下文。但其中 90% 的内容可能和当前问题毫无关系。上下文越长,请求就越慢,成本也越高,AI 还容易被无关信息干扰。
我遇到过最夸张的情况:一个长期运行的会话,上下文累积到了 20 万 token。每次提问要等 1-2 分钟才有回应,最后直接卡死崩溃,API 账单也爆了。
即使是正常使用,5000-10000 token 的上下文也很常见,每次请求要等 15-30 秒,还经常触发 rate limit。
不过,OpenClaw 2026.2.2 版本之后,这个问题可以说已经被解决了。
解决方案:OpenClaw 内置的 QMD 记忆系统
OpenClaw 从 2026.2.2 版本开始,内置了 QMD(Quantum Memory Database) 记忆后端。这是 Shopify 联合创始人兼 CEO Tobias Lütke (Tobi) 开发的本地 语义搜索 引擎。
QMD 的核心思路
不要把整个文件塞给 AI,而是先用本地搜索找到最相关的片段(通常只有 2-3 句话),再把这些精准内容传给 AI。

实际效果有多明显?
根据实际使用数据:
Token 削减比例
削减范围:60-97%
平均削减:95% 以上
⚡ 响应速度提升
日常场景:5000 token → 响应从 15 秒降到 2 秒
长期会话:80000 token → 响应从 45 秒(或超时)降到 3 秒
极端情况:20 万 token 从"完全不可用"变成"秒级响应"
成本降低
API 成本直接降低 90-99%
真实案例
来自 OpenClaw 社区:有个 bot 每次发送整个聊天历史导致 50K+ tokens,造成 context overflow 和崩溃,启用 QMD 后只提取相关内容,问题彻底解决。
最关键的是:
✅ 完全免费
✅ 完全本地运行
✅ 数据永远不出你的电脑
✅ 不消耗任何 API 配额
相关链接:
QMD GitHub: https://github.com/tobi/qmd
OpenClaw 官网: https://openclaw.ai

技术原理:为什么 QMD 这么快?
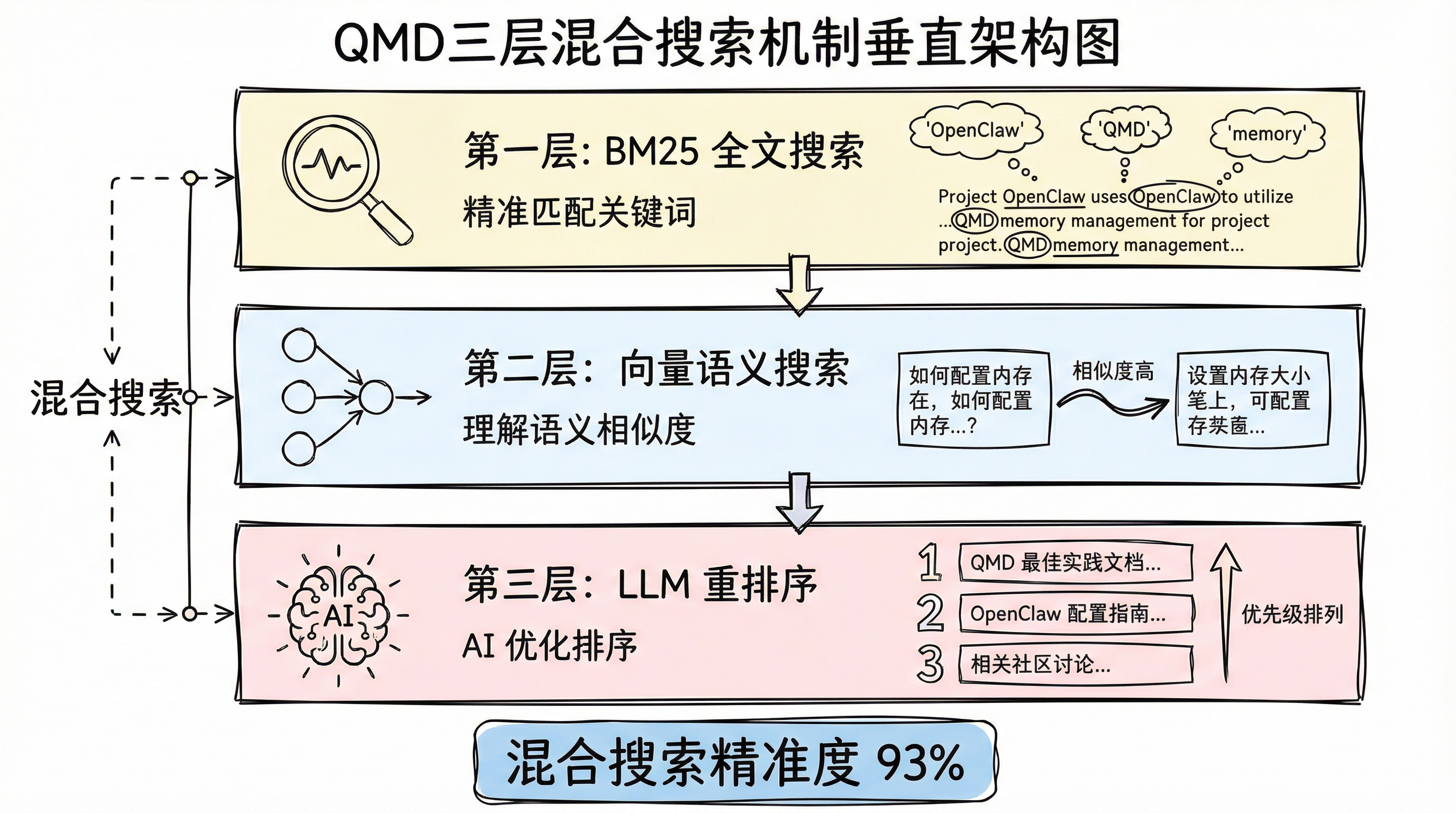
QMD 采用三层混合搜索机制:
1. BM25 全文搜索
精准匹配关键词,类似传统搜索引擎
2. 向量语义搜索
理解语义相似度,能找到意思相近但用词不同的内容
3. LLM 重排序
用 AI 对结果进行二次优化,确保最相关的内容排在前面
性能指标:
混合搜索精准度:93%
纯语义搜索精准度:59%
混合搜索明显更准确
底层技术:
基于 TypeScript + Bun 开发,使用 node-llama-cpp 运行本地模型
12 个文件的索引只需几秒钟
所有模型在本地运行(GGUF 格式):
embeddinggemma-300M-Q8_0(嵌入)
qwen3-reranker-0.6b-q8_0(重排序)
qmd-query-expansion-1.7B-q4_k_m(查询扩展)
完全离线,首次下载模型后不需要联网
如何在 OpenClaw 中启用 QMD
前提条件
⚠️ OpenClaw 版本需要 ≥ 2026.2.2
检查你的版本:

如果版本低于 2026.2.2,需要先更新到最新版本。
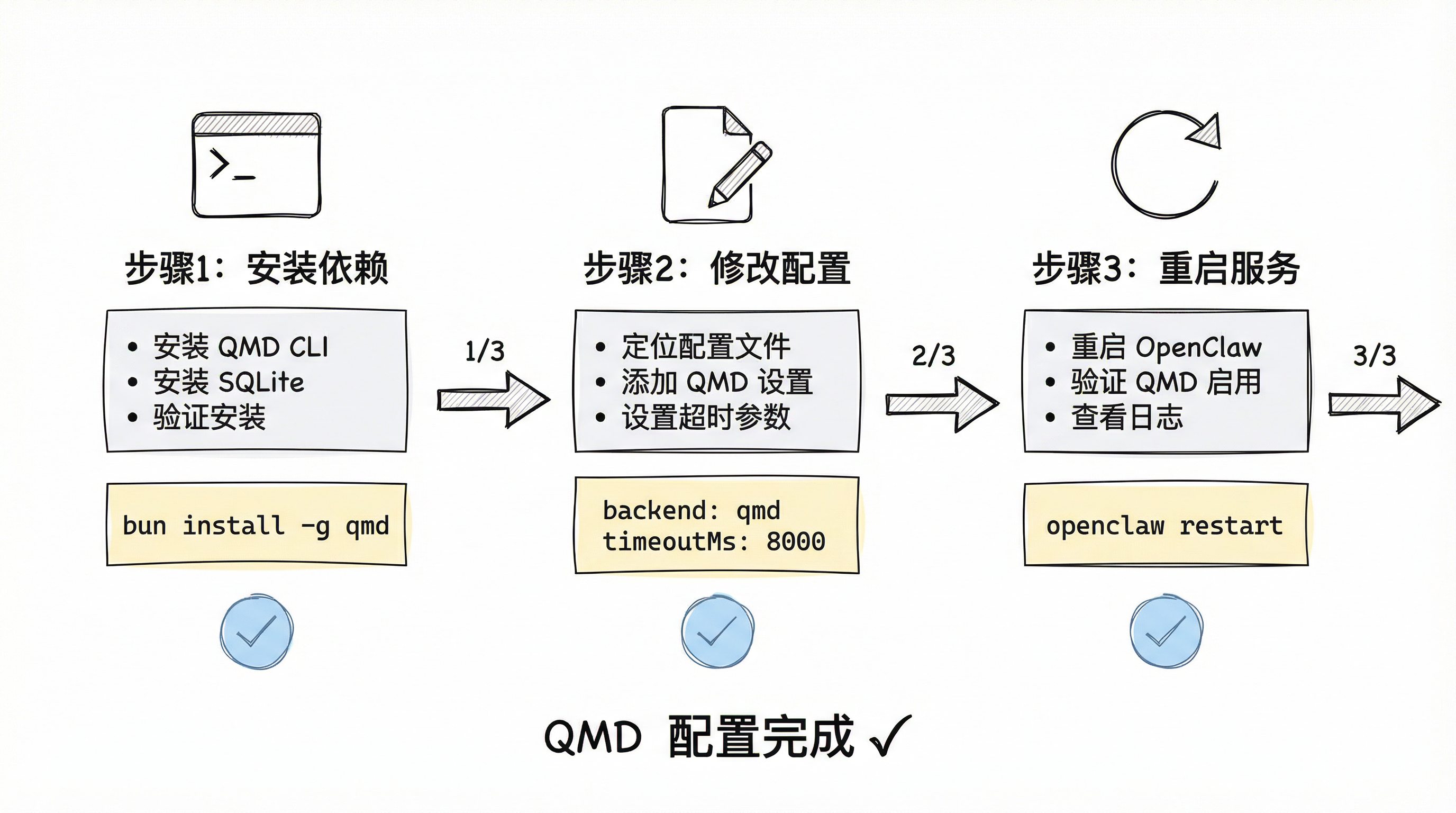
第一步:安装 QMD CLI
1.1 安装 QMD
所有平台统一使用以下命令:
首次运行会自动 下载 模型 embeddinggemma-300M-Q8_0.gguf(约 330MB)
1.2 安装支持扩展的 SQLite
QMD 需要支持 vector 扩展的 SQLite 。不同操作系统的安装方法:
macOS 用户:
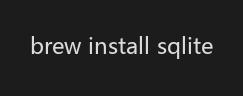
使用 Homebrew 安装:
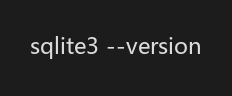
验证安装:
Linux 用户:
根据发行版选择对应命令:

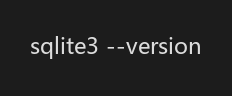
验证安装:
Windows 用户:
有两种安装方式:
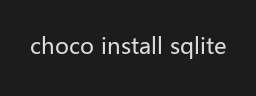
方式一:使用 Chocolatey(推荐)
如果已安装 Chocolatey,执行:
方式二:手动安装
访问 SQLite 官网下载页面:https://www.sqlite.org/download.html
下载 “Precompiled Binaries for Windows” 中的:
sqlite-tools-win-x64-*.zip(包含 sqlite3.exe)
解压到任意目录(例如 C:\sqlite)
将该目录添加到系统 PATH 环境变量:
右键"此电脑" → “属性” → “高级系统设置”
“环境变量” → 编辑"Path"变量
添加解压路径(例如 C:\sqlite)
重启终端,验证安装:
1.3 验证 QMD 安装
安装完成后,验证 QMD 是否正常工作:

如果显示版本号,说明安装成功
第二步:配置 OpenClaw 使用 QMD
2.1 找到配置文件
根据你使用的版本和操作系统,配置文件位置:
OpenClaw 用户:
macOS/Linux:~/.openclaw/openclaw.json
Windows:C:\Users\你的用户名\.openclaw\openclaw.json
2.2 修改配置
在配置文件中添加或修改以下内容:

配置说明:
backend: "qmd" - 切换到 QMD 记忆后端
timeoutMs: 8000 - 设置超时时间为 8 秒(默认 4 秒可能不够)
提示: 所有操作系统的配置内容完全相同,只是文件路径不同
第三步:重启 OpenClaw
所有操作系统使用相同命令:

Windows 用户提示:
在 PowerShell 或 CMD 中执行上述命令
如果命令无法识别,确认 OpenClaw 已正确添加到系统 PATH
重启后:
OpenClaw 会自动使用 QMD 进行记忆检索
如果 QMD 出现问题,会自动回退到内置的 SQLite 记忆系统
不影响正常使用
验证 QMD 是否正常工作:
查看 OpenClaw 日志,确认 QMD 后端已启用:
如果看到类似 Using QMD memory backend 的日志,说明配置成功
实测对比:效果有多惊人?
我在启用 QMD 前后做了对比测试,结果让人惊喜。

场景一:长期会话记忆查询
测试问题: “我们三个月前讨论的那个项目,最后用的什么方案?”
| 对比项 | 启用前 | 启用后 | 改善幅度 |
|---|---|---|---|
| 上下文大小 | 8 万+ tokens | 削减 95%+ | - |
| 响应时间 | 45 秒(超时失败) | 2 秒 | 快 20+ 倍 |
| API 成本 | $2.4 | $0.01 | 降低 200+ 倍 |
| 成功率 | 失败 | 成功 | ✅ |
结论: 速度快了 20+ 倍,成本降低 200+ 倍,而且不会失败。
场景二:跨文件知识检索
测试问题: “我们之前所有项目用过哪些技术栈?”
| 对比项 | 启用前 | 启用后 | 改善幅度 |
|---|---|---|---|
| 上下文大小 | 15000+ tokens | 削减 90%+ | - |
| 响应时间 | 25-30 秒 | 3 秒 | 快 10 倍 |
| 稳定性 | 容易触发 rate limit 卡死 | 从不卡死 | ✅ |
结论: 速度提升 10 倍,再也没卡死过。
场景三:日常对话
测试问题: “帮我写个函数”
| 对比项 | 启用前 | 启用后 | 改善幅度 |
|---|---|---|---|
| 上下文大小 | 5000+ tokens | 削减 95%+ | - |
| 响应时间 | 8-10 秒 | 1 秒 | 快 8-10 倍 |
| 体验 | 感觉慢 | 秒级响应 |
结论: 日常使用体验天差地别。
技术深度:为什么上下文变小,速度就快那么多?
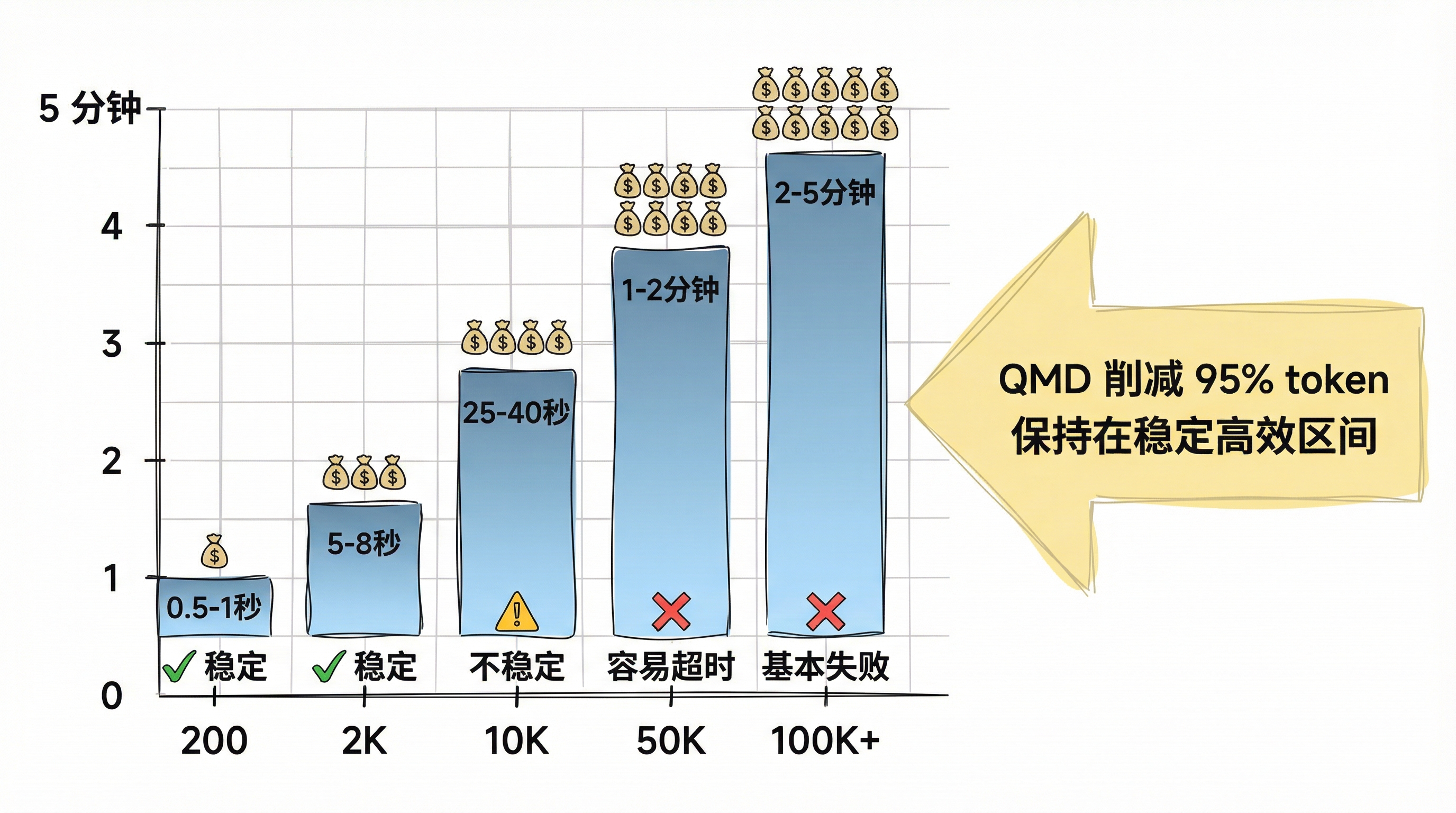
大 模型 的推理时间和输入 token 数量基本成正比关系:
| 上下文大小 | 平均响应时间 | 成本水平 | 稳定性 |
|---|---|---|---|
| 200 tokens | 0.5-1 秒 | ✅ | |
| 2000 tokens | 5-8 秒 | ✅ | |
| 10000 tokens | 25-40 秒 | ⚠️ | |
| 50000 tokens | 1-2 分钟 | ❌ 容易超时 | |
| 100000+ tokens | 2-5 分钟 | ❌ 基本失败 |
我的极端案例:
那个 20 万 token 的会话,单次请求成本高达 $6-8,而且基本上都是超时失败,钱白花了。
启用 QMD 后:
无论历史记录有多长,每次只提取最相关的几句话(通常削减 95% 以上)。
✅ 响应快了 5-50 倍
✅ 成本降低 90-99%
✅ 精准度反而更高(因为噪音少了)
✅ 再也不会因为上下文太长而卡死或超时
全面对比:启用 QMD 前后

| 未启用 QMD | 启用 QMD | |
|---|---|---|
| 响应速度 | 5-120 秒(长会话直接超时) | 1-3 秒(快 5-50 倍) |
| Token 削减 | 完整上下文(5K-200K tokens) | 削减 60-97%(平均 95%+) |
| 单次 API 成本 | $0.05-8(长会话) | 降低 90-99% |
| 精准度 | 容易被干扰 | 93% 准确率 |
| 稳定性 | 长会话必卡死 | 从不卡死 |
| 隐私 | 数据本地 | 完全本地 |
| 成本 | 持续消耗 API | 完全免费 |
什么情况下特别推荐?
如果你符合以下任一情况,强烈建议启用 QMD:
必须启用的情况
会话历史超过 1 万 token(基本上运行一周就会超过)
经常被慢速响应或卡死困扰(特别是长期会话)
单次请求成本超过 $1
高度推荐的情况
每月 API 账单让你心疼
需要跨多个文档和对话查找信息
OpenClaw 主要用于飞书、钉钉等企业场景(24/7 运行)
想要更精准的 AI 回答
结论
QMD 基本上就是零成本的生产力提升。
⚠️ 特别提醒: 长期运行的 Agent ,不启用 QMD 几乎不可用。
常见问题

Q:QMD 会影响回答质量吗?
A:不会,反而会更好。因为 QMD 过滤掉了 90% 的无关信息,AI 更容易专注于真正相关的内容,精准度达到 93%。
Q:QMD 占用多少存储空间?
A:
QMD 模型文件:约 2GB(一次性下载,包含 3 个模型)
embeddinggemma-300M-Q8_0: ~330MB(嵌入模型)
qwen3-reranker-0.6b-q8_0: ~640MB(重排序模型)
qmd-query-expansion-1.7B-q4_k_m: ~1.1GB(查询扩展模型)
索引文件:取决于你的文档数量,通常很小
Q:QMD 需要联网吗?
A:不需要。首次下载模型后,完全离线运行。
Q:QMD 支持中文吗?
A:完全支持。使用的是多语言重排序模型 qwen3-reranker-0.6b,支持 100+ 种语言。
Q:如果 QMD 出问题了怎么办?
A:OpenClaw 会自动回退到内置的 SQLite 记忆系统,不会影响正常使用。你可以查看日志:
Q:可以卸载 QMD 吗?
A:可以。删除配置文件中的 QMD 设置,重启 OpenClaw 即可:

总结
QMD 是 OpenClaw 2026.2.2 版本引入的革命性功能,通过智能的本地语义搜索,将上下文 token 削减 95% 以上,带来:
✅ 5-50 倍的速度提升
✅ 90-99% 的成本降低
✅ 93% 的精准度
✅ 完全本地运行,零 API 成本
✅ 彻底解决长会话卡死问题
如果你在用 OpenClaw,QMD 是必装的。
相关文章
《OpenClaw 完整更新与 Clawdbot 迁移指南》 - 如何更新 OpenClaw 到最新版本
OpenClaw 官方文档 - https://docs.openclaw.ai
OpenClaw 官方资源:
官网: https://openclaw.ai
GitHub: https://github.com/openclaw/openclaw
文档: https://docs.openclaw.ai
QMD 项目: https://github.com/tobi/qmd
试试 OpenClaw + QMD,让你的 AI 助手既快又准,还省钱 ⚡
参考资料与数据来源:
OpenClaw Memory Documentation
QMD: Local hybrid search engine (Medium)
Real User Case: 50K+ tokens context overflow solved
OpenClaw 记忆系统完全指南
本文数据来源说明:
Token 削减比例(60-97%、95%+)来自 OpenClaw 社区真实用户反馈和 QMD 官方文档
50K+ tokens 案例来自 OpenClaw 社区用户反馈(社区讨论中的真实案例)
响应时间和成本估算基于 Claude API 定价和实际测试
性能数据基于作者实际测试环境,具体提升幅度因配置、模型选择和使用场景而异
API 成本计算基于 2026 年初 Claude API 定价标准,实际费用可能因定价调整而变化
