【数据结构与算法】经典四大练手排序算法超全解析:思想、步骤、代码与时间复杂度
前言
排序算法是数据结构的核心基础内容,也是编程学习与算法面试的必考重点。虽然 C/C++ 已提供内置排序函数,但学习各类经典排序算法,不仅能理解分治、贪心、递归等核心思想,还能锻炼代码逻辑、边界处理、bug 调试及复杂度分析能力。掌握插入、选择、冒泡、堆排序等原理与实现,能为后续高阶算法、程序优化打下扎实根基。
一、为什么要学排序?
可能同学在学习排序算法的时候会有⼀个疑惑:无论是C还是C++,都已经提供了sort 函数,为什么还要花大量的时间去学习排序 算法 呢?不如把时间用在学习别的算法上。这个想法是片面的。
• 虽然接下来要学习的排序算法,在以后⼀半以上甚至是全部都不会用到。但是,不要单纯的想着往用到它们。这些算法思想,将会伴随我们学习后面的知识。比如堆排序中的贪贪心思想,归并排序 里面的分治思想,快速排序里面的递归思想等。学习这些算法能起到预习的作用,后续学到对应算法的时候能够更加得心应手。
• 除了算法思想,我们在学习这些算法的过程中,还会锻炼:如何处理写代码时的细节问题,如何优化算法,遇见bug如何调试,分析时空复杂度等等。
因此,希望大家不要抱着无所谓的心态来学习排序算法,还是需要重视起来。能做到每⼀种排序算法都能理解 原理
,掌握算法流程以及时空复杂度,并且能用代码实现出来。
代码能力其实是慢慢培养的,大家写的每一行代码都是不会白费的。
二、插入排序
插入排序(Insertion Sort)类似于玩扑克牌插牌过程:

2.1 算法思想与步骤
基本思想:每次将⼀个待排序的元素按照其 关键字 大小插入到前面已排好序的序列中,按照该种方式将所有元素全部插入完成即可。
步骤:
初始化:将列表分为已排序部分和未排序部分。初始时,已排序部分只包含第一个元素,未排序部分包含剩余元素。
选择元素:从未排序部分中取出第一个元素。
插入到已排序部分:将该元素与已排序部分的元素从后向前依次比较,找到合适的位置插入。
重复步骤:重复上述步骤,直到未排序部分为空,列表完全有序。
2.2 实现代码
#include <iostream> using namespace std; const int N = 1e5 + 10; int a[N], n; void insert_sort(int a[], int n) { //偏离待排序元素 for (int i = 2; i <= n; i++) // 第⼀个位置默认就是有序的 { int key = a[i]; int j = i - 1; while (j >= 1 && a[j] > key) { a[j + 1] = a[j]; j--; } a[j + 1] = key; } } int main() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; insert_sort(a, n); for (int i = 1; i <= n; i++) cout << a[i] << " "; return 0; }
2.3 时间复杂度分析
• 当整个序列有序的时候,插入排序最优,此时时间复杂度为O(n) 。
• 当整个序列逆序的时候,每个元素都要跑到最前⾯,时间复杂度为O(n ) 。
三、选择排序
3.1 算法思想与步骤
基本思想:选择排序(Selection Sort)是⼀种特别直观的排序算法。每次找出未排序序列中最小的元素,然后放进有序序列的后面。
步骤:
初始化:将列表分为已排序部分和未排序部分。初始时,已排序部分为空,未排序部分为整个列表。
查找最小值:在未排序部分中查找最小的元素。
交换位置:将找到的最小元素与未排序部分的第一个元素交换位置。
更新范围:将未排序部分的起始位置向后移动一位,扩大已排序部分的范围。
重复步骤:重复上述步骤,直到未排序部分为空,列表完全有序。
3.2 实现代码
//选择排序 #include <iostream> using namespace std; const int N = 1e5 + 10; int a[N], n; void selection_sort(int a[], int n) { for (int i = 1; i <= n; i++) //待排序区间的第一个位置 { //[i,n]待排序区间 int pos = i; for (int j = i + 1; j <= n; j++) { if(a[i] > a[j]) pos = j; } swap(a[i], a[pos]); } } int main() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; selection_sort(a, n); for (int i = 1; i <= n; i++) cout << a[i] << " "; return 0; }
3.3 复杂度分析
无论数组有序还是无序序,在未排序区间内找最小值的时候,都需要遍历⼀遍待排序的区间,因此时间复杂度为O(n ) 。
四、冒泡排序
冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复地遍历待排序的列表,比较相邻的元素并交换它们的位置来实现排序。该算法的名称来源于较小的元素会像"气泡"一样逐渐"浮"到列表的顶端。
4.1 算法思想与步骤
基本思想:每次检查相邻两个元素,如果前面的元素与后面的元素满足给定的排序条件,就将相邻两个元素交换。当没有相邻的元素需要交换时,排序就完成了
步骤:
比较相邻元素:从列表的第一个元素开始,比较相邻的两个元素。
交换位置:如果前一个元素比后一个元素大,则交换它们的位置。
重复遍历:对列表中的每一对相邻元素重复上述步骤,直到列表的末尾。这样,最大的元素会被"冒泡"到列表的最后。
缩小范围:忽略已经排序好的最后一个元素,重复上述步骤,直到整个列表排序完成。
4.2 实现代码
//冒泡排序 #include <iostream> using namespace std; const int N = 1e5 + 10; int a[N], n; void bubble_sort(int a[], int n) { // 依次枚举待排序区间的最后⼀个元素 for (int i = n;i >1; i++) { int flag = 0; //[i,n]待排序区间 for (int j = 1; j < n; j++) { if (a[j] > a[j + 1]) { flag = 1; swap(a[j], a[j + 1]); } } if (flag == 0) return; } } int main() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; bubble_sort(a, n); for (int i = 1; i <= n; i++) cout << a[i] << " "; return 0; }
4.3 复杂度分析
• 如果数组有序,只会扫描⼀遍,时间复杂度为O(n) 。
• 如果逆序,所有元素都会向后冒一次到合适位置,时间复杂度为O(n ) 。
五、堆排序
堆排序(Heap Sort)是指利用堆这种 数据结构 所设计的⼀种排序算法。本质上是优化了选择排序算法,如果将数据放在堆中,能够快速找到待排序元素中的最小值或最大值。

5.1 算法思想与步骤
基本思想:利用堆的特性调整数组
步骤:
建堆。升序建大堆,降序建小堆
建堆过程,从倒数第一个非叶子节点开始,倒着⼀直到根结点位置,每个结点进行向下调整。
排序。删除堆顶的逻辑。
每次将堆顶元素与堆中最后⼀个元素交换,然后将堆顶元素往下调整。直到堆中剩余⼀个元素,所有元素就都有序了。
5.2 实现代码
#include <iostream> using namespace std; const int N = 1e5 + 10; int a[N], n; void down(int parent,int n) { int child = parent * 2; while (child <= n) { if (child + 1 <= n && a[child] < a[child + 1]) child++; if (a[child] > a[parent]) swap(a[child], a[parent]); else break; parent = child; child = parent * 2; } } void heap_sort(int a[], int n) { //建堆 for (int i = n / 2; i >= 1; i--) down(i, n); for (int i = n; i > 1; i--) { swap(a[i], a[1]); down(1, i - 1); } } int main() { cin >> n; for (int i = 1; i <= n; i++) cin >> a[i]; heap_sort(a, n); for (int i = 1; i <= n; i++) cout << a[i] << " "; return 0; }
5.3 复杂度分析
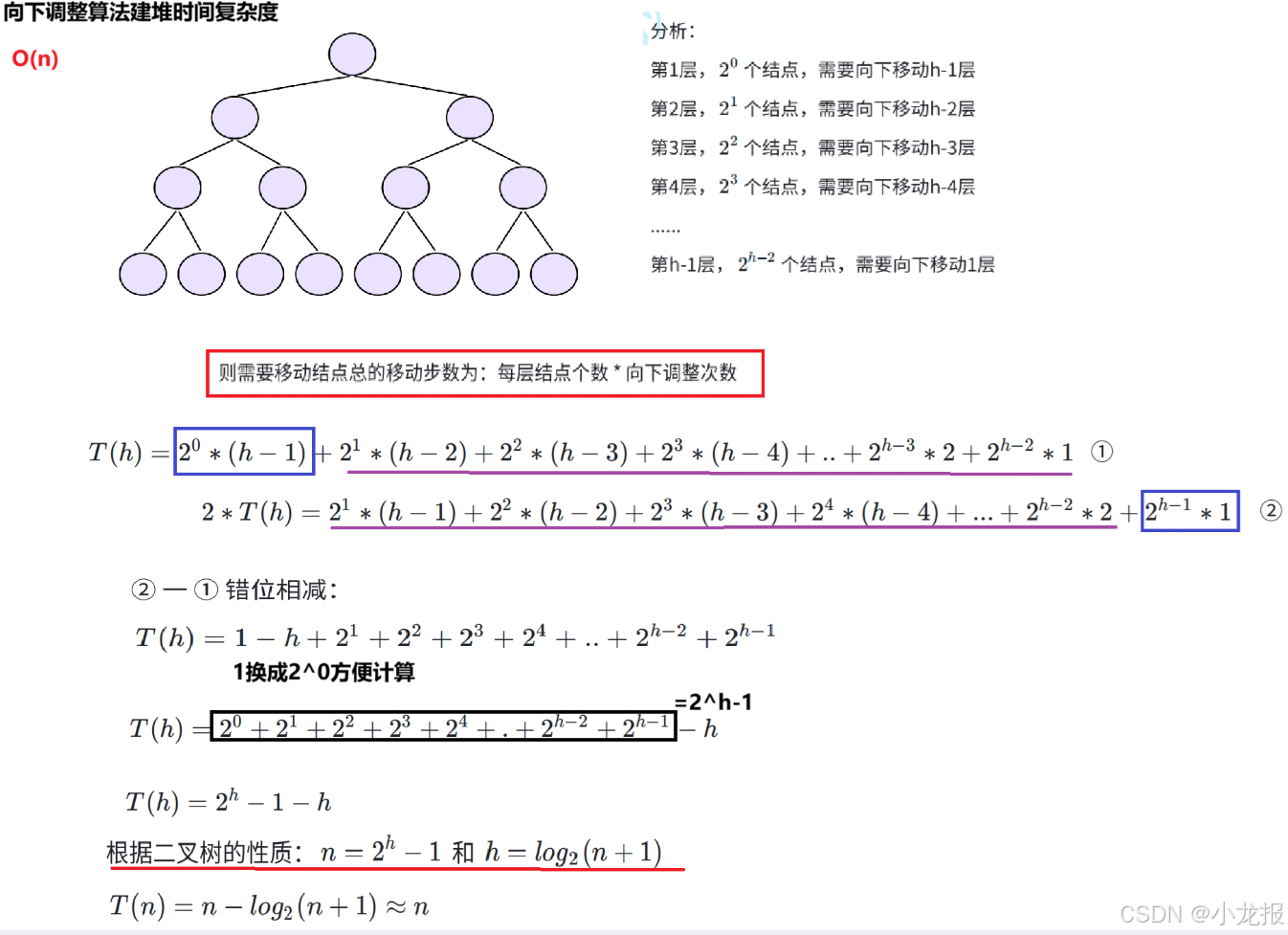
综上所述,堆排序的时间复杂度主要取决于排序的过程,也就是nlog n 。
