【初阶数据结构】 升沉有序的平仄 排序
在学习编程中,把无序的东西变的有序在生活中很常见,排序算法的复杂度对我们算法优劣还是有很大的影响
进入排序讲解之前我要教大家写 测试用例 ,来测试我们写的排序的快慢
分为四步走:
在堆上创建N个数据的空间
种时间种子,用循环将生成的随机数,加入到开辟的空间中去
利用time.h里面的begin(),end()函数,记录当前的时间,和程序结束的时间,然后相减,得到程序运行的时间
释放开辟的空间,防止内存泄漏
void TestOP() { int N = 100000; srand((unsigned int )time(0)); int* a1 = (int*)malloc(sizeof(int) * N); int* a2 = (int*)malloc(sizeof(int) * N); for (int i = 0; i < N; i++) { a1[i] = rand()+i; //a1[i] = rand(); a2[i] = a1[i]; } int begin1 = clock(); InsertSort(a1, N); int end1 = clock(); int begin2 = clock(); ShellSort(a2, N); int end2 = clock(); printf("InsertSort>:%d\n", end1 - begin1); printf("ShellSort>: %d\n", end2 - begin2); free(a1); free(a2); }
排序分类
以下是我要讲的全部排序,当然这一次性肯定讲不完,我会看情况分为两次或者三次讲完
1. 插入排序
>直接插入排序<
图是很清楚默认排的是升序,
遇到小的就往前插入,直到遇到,比自己小的停止,这种效率还是很高的,时间复杂度虽然是O(N^2) , 但出现O(N^2), 情况还是比较难,要求是高度升序才有可能,所以作为O(N^2)的排序方式还是比较快的.
以下是代码实现演示过程
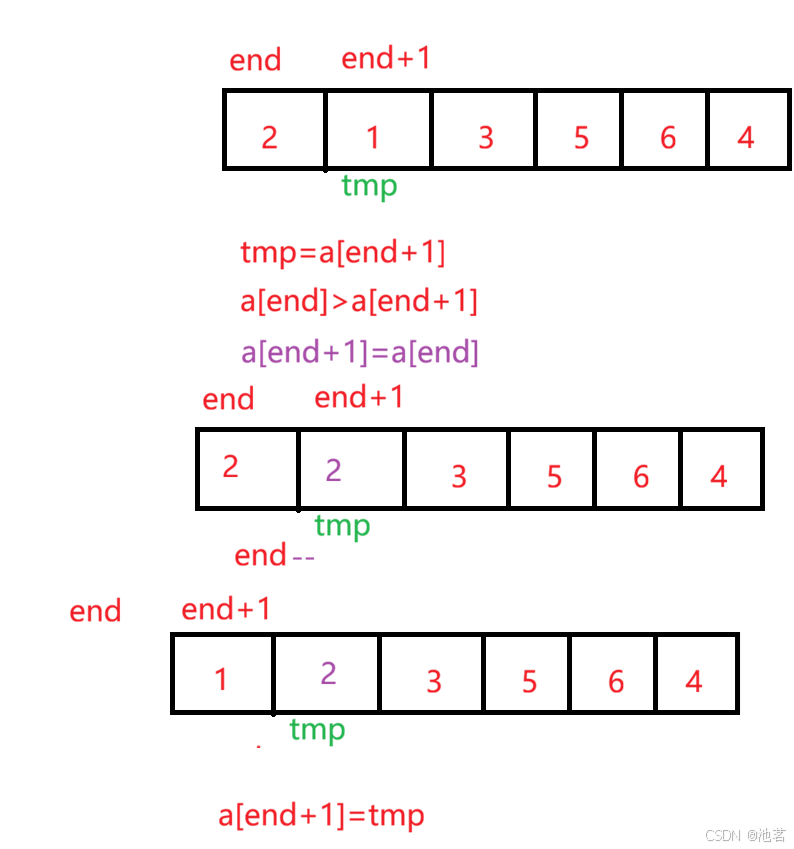
void InsertSort(int* a, int n) { for (int j = 0; j < n - 1; j++) { int end = j; int tmp = a[end + 1]; //////////////////////////////// while(end >= 0) { if (a[end] > tmp){ a[end + 1] = a[end];//核心区别 end--; } else{ break; } a[end + 1] = tmp; } //////////////////////////////// } }
上面的插入排序是我自己写的,逻辑上正确,但是效率略低,我每次a[end]=a[end+1],就需要没每次更新一下值a[end+1]=tmp
但实际上可以采用a[end+1]=a[end],这样就可以在每次结束时值赋值一次a[end+1]=tmp就行
标准写法主要区别就在我框出来的部分
void InsertSort(int* a, int n) { for (int j = 0; j < n - 1; j++) { int end = j; int tmp = a[end + 1]; /////////////////////////////////// while (end >= 0 && a[end] > tmp) { a[end + 1] = a[end];//核心区别 end--; } a[end + 1] = tmp; ///////////////////////////////// } }
>希尔排序<
希尔排序时间复杂度为O(N^1.3),不用掌握计算,因为需要很多数学的专业知识
从上面看出其实选择排序这个结构还是很不错的一个结构,我们能不能改进一下结构,让他的排序速度变快呢?
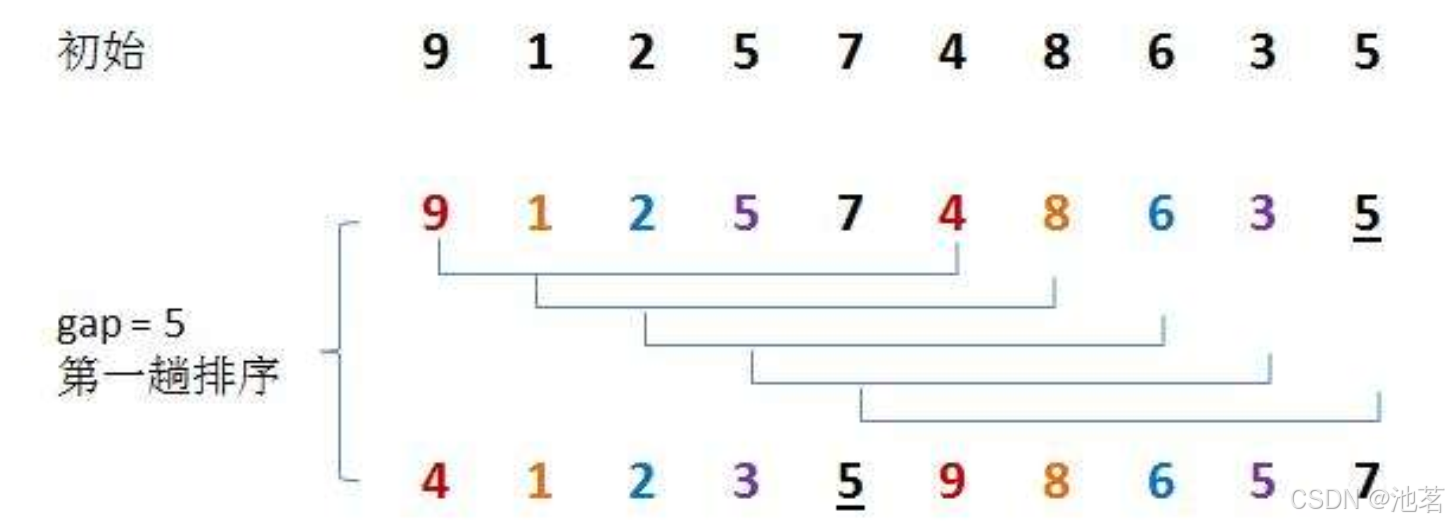
我们可以看出与插入排序对比,希尔排序多了一个gap组
gap的选取,有大量验证,gap/3得到的排序速度最快,gap/3+1是为了保证gap不为零,gap既是组数又是一次跳的步数,
gap是干什么用的呢?
gap是用来把我们的数据分割成gap组分别进行直接插入排序
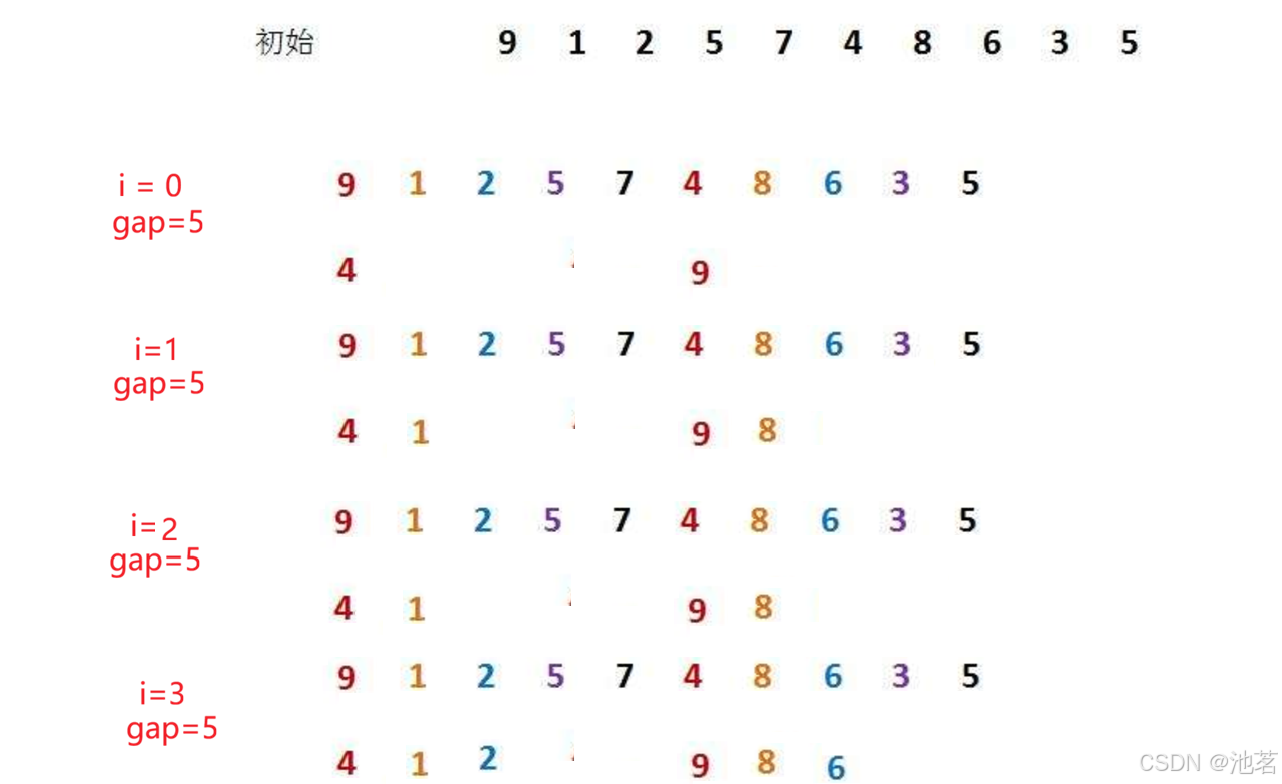
如图所示
第二个循环的过程,随i变化,分别开始,进行直接插入排序,那结束条件是什么?
第二个循环的结束条件
最外层调整gap使得gap等于1时最后一次排序

void ShellSort(int* a, int n){ int gap = n; while (gap > 1){ gap = gap / 3 + 1; for (int i = 0; i < n - gap; i++){ int end = i; int tmp = a[end + gap]; while (end >= 0){//类比直接插入排序,把1换成gap if (a[end] > tmp){//这里间隔是gap所有加减都gap a[end + gap] = a[end]; end -= gap; } else break; a[end + gap] = tmp; } } } }
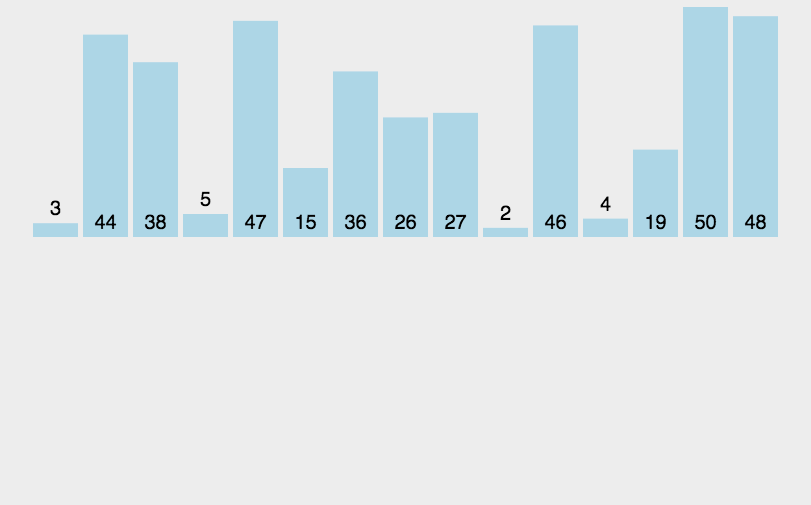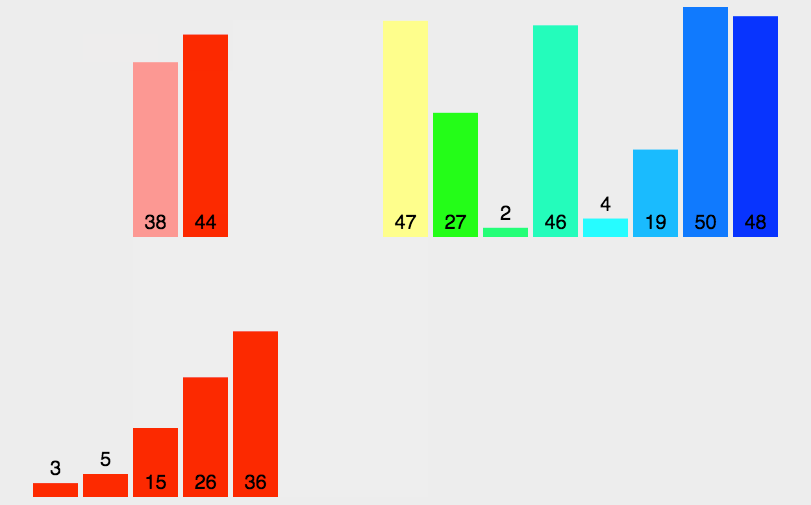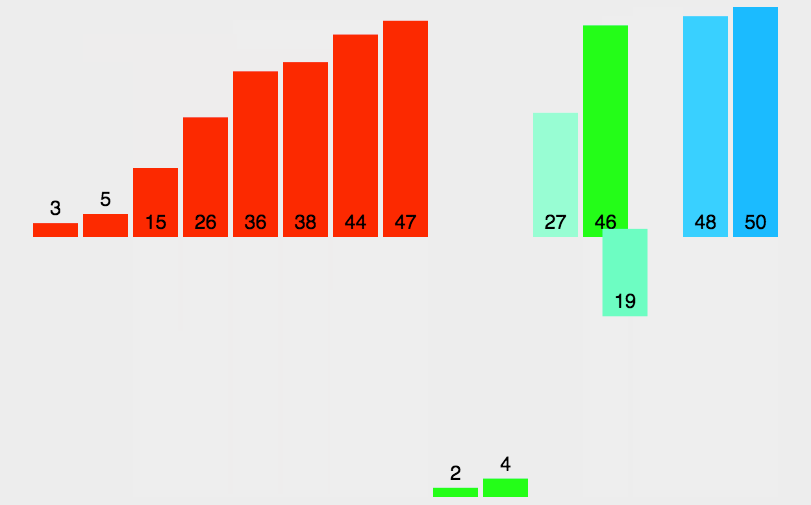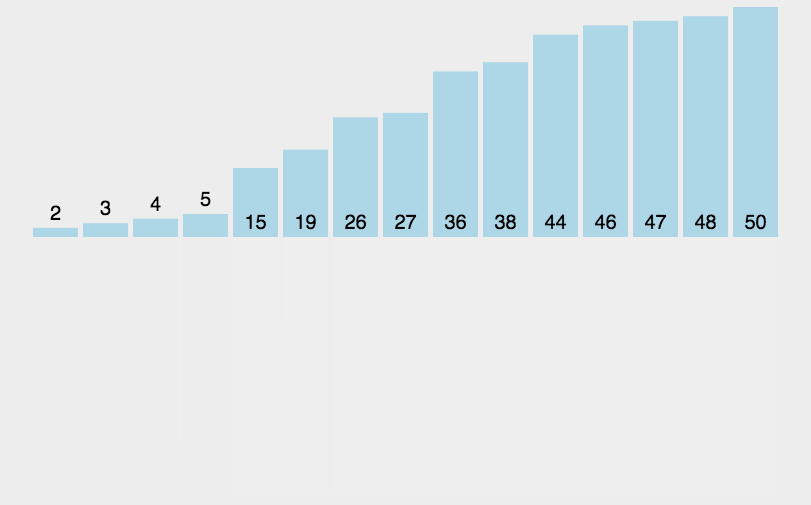
对比一下1000000个数据下,直接插入排序和希尔排序的速度
可以看出差距还是挺大的

2. 选择排序
>选择排序<
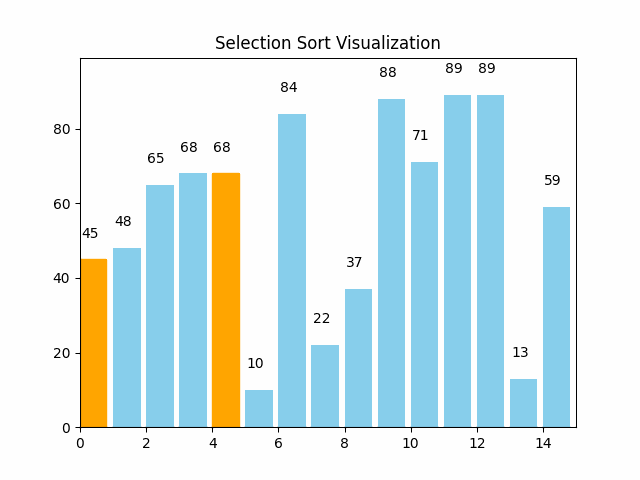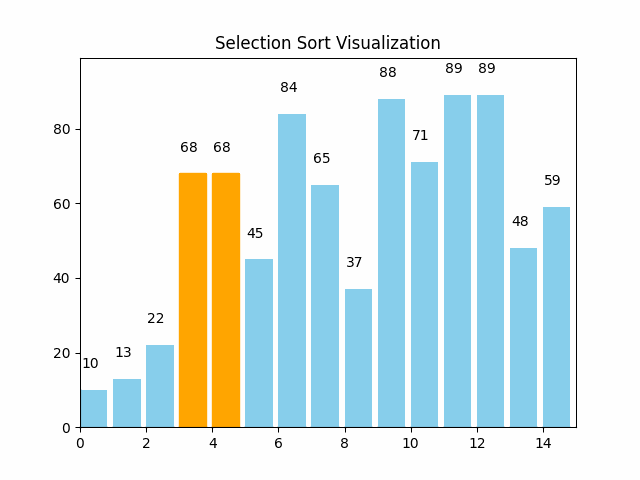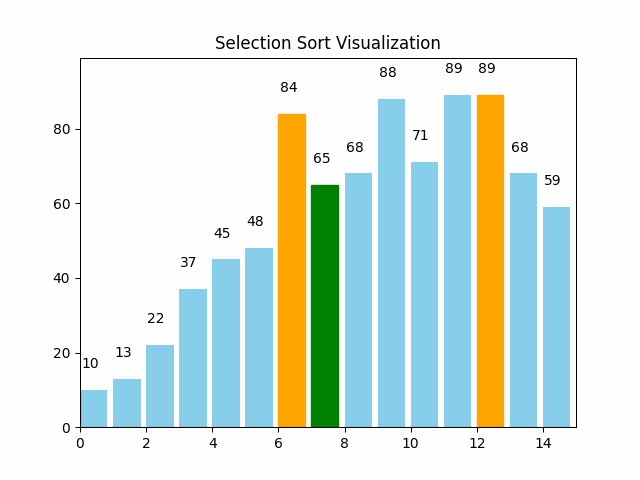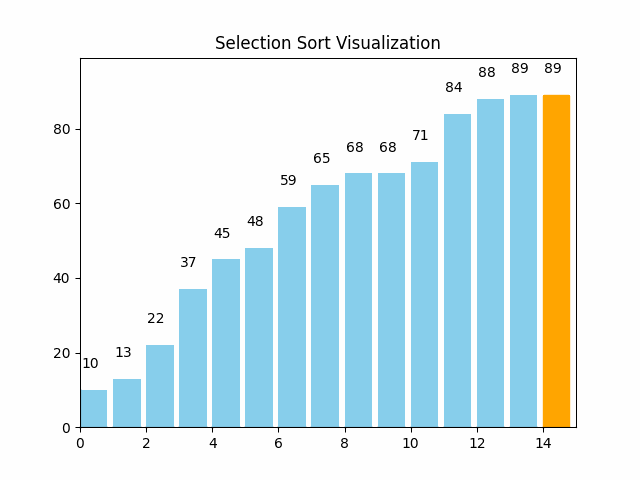
这里逻辑很简单,就是每轮遍历,选出最大最小的,放在begin和last位置处
**注意:**这里当begin与max相重合时,Swap(&a[begin], &a[min]);后a[max]被交换到a[min]的位置要更新max位置

void SelectSort(int* a, int n) { int begin, last, min, max;; begin = 0; last = n - 1; while (begin < last) { min = max = begin; for (int i = begin + 1; i <= last; i++) { if (a[i] > a[max]) { max = i; } if (a[i] < a[min]) { min = i; } } Swap(&a[begin], &a[min]); if (max == begin)//坑点,如果相等要进行更新max { min = max; } Swap(&a[last], &a[max]); begin++; last--; } }
>堆排序<
我这里演示的是建大堆排升序
思路是每次把最大的数据堆顶数据与堆的最后一个数据交换位置, size
- -;
再重新找次大的数据,再重复此过程
下面演示堆的建堆过程还有排序过程

void HeapDown(int* a, int size,int parent) { int child = 2 * parent + 1; while (child < size) { if (child+1<size && a[child + 1]>a[child]) { child++; } if (a[parent] < a[child]) { Swap(&a[parent], &a[child]); parent = child; child = 2 * parent + 1; } else { break; } } } void HeapSort(int* a,int size) { for (int i=size;i>1;i--) { Swap(&a[0], &a[i - 1]); HeapDown(a, i-1,0); } }
堆排序与选择排序对比100000,由于选择排序太慢,这里就用十万个数据

由此看出直接插入排序还是比选择排序快很多的
3. 归并排序
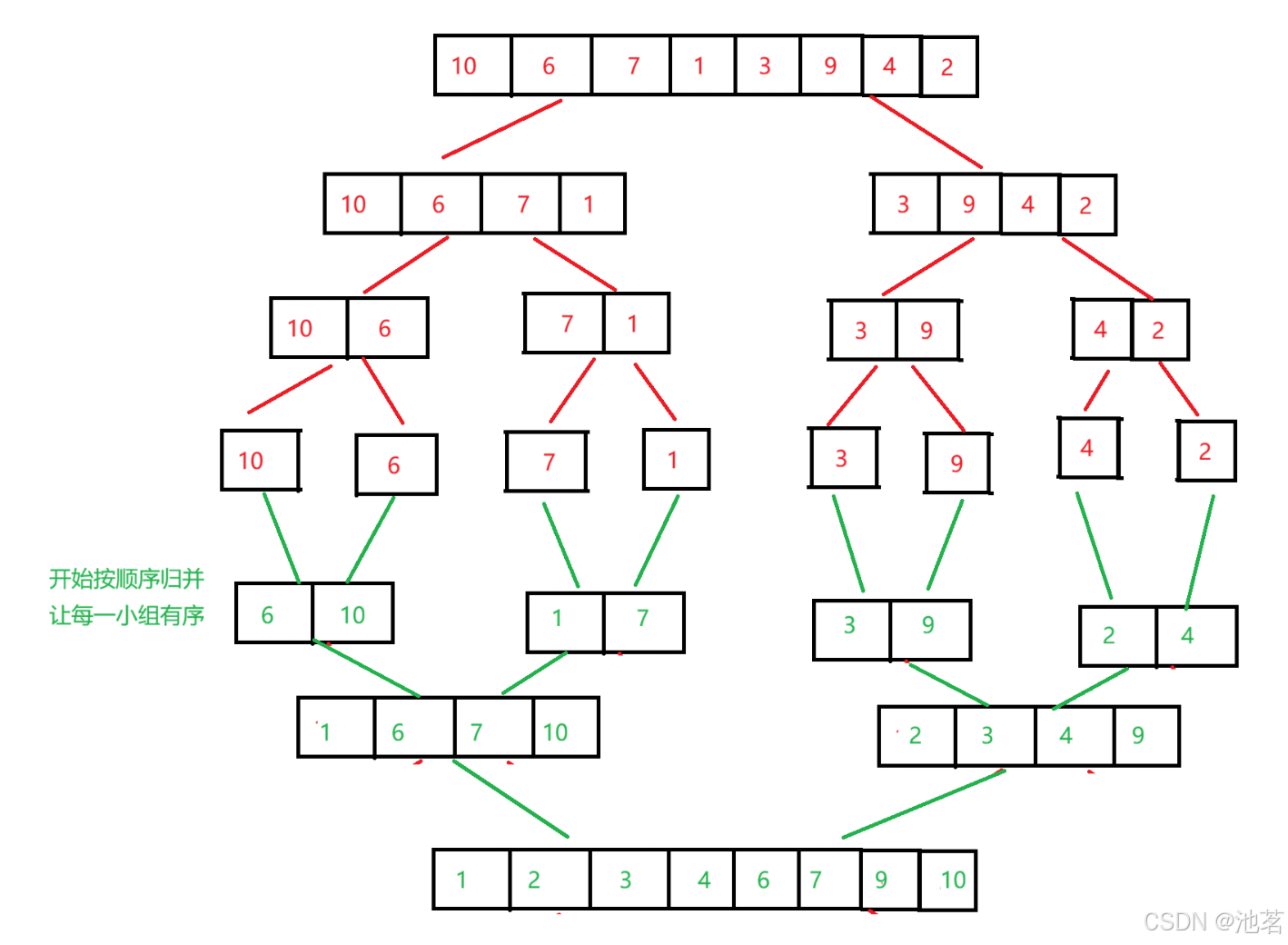
>归并排序递归实现<
归并是一种分而治之的思想,先分成小组,单个的,再进行顺序归并
再这里最坏分割时间复杂度是O(logN)
注意这里在分割区间时的小细节问题

void _Mergesort(int* a, int*tmp, int begin,int end) { if (begin == end) return; else { int mid = (begin + end) / 2; //begin==end返回这里往下走,进行有序合并,就像顺序表篇讲的合并有序数组 _Mergesort(a,tmp,begin, mid); _Mergesort(a,tmp, mid + 1, end); int begin1 = begin; int end1 = mid; int begin2 = mid + 1; int end2 = end; int i = 0; while (begin1 <= end1 && begin2 <= end2) {//有序合并 if (a[begin1] < a[begin2]) { tmp[i++]= a[begin1++]; } else { tmp[i++] = a[begin2++]; } } //有一组有剩余,拷贝到tmp中去 while (begin1 <= end1) { tmp[i++] = a[begin1++]; } while (begin2 <= end2) { tmp[i++] = a[begin2++]; } //注意着里要从begin开始拷贝,拷贝回a中 //拷贝回去是从a[begin]拷,对于最左边begin=0,但对于其他的递归分割的begin却不是0 memcpy(a+begin, tmp, sizeof(int) * (end - begin + 1)); } } void Mergesort(int* a,int n) { int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("malloc fail"); return; } _Mergesort(a,tmp,0,n-1); free(tmp); tmp = NULL; }

>归并排序的非递归实现<
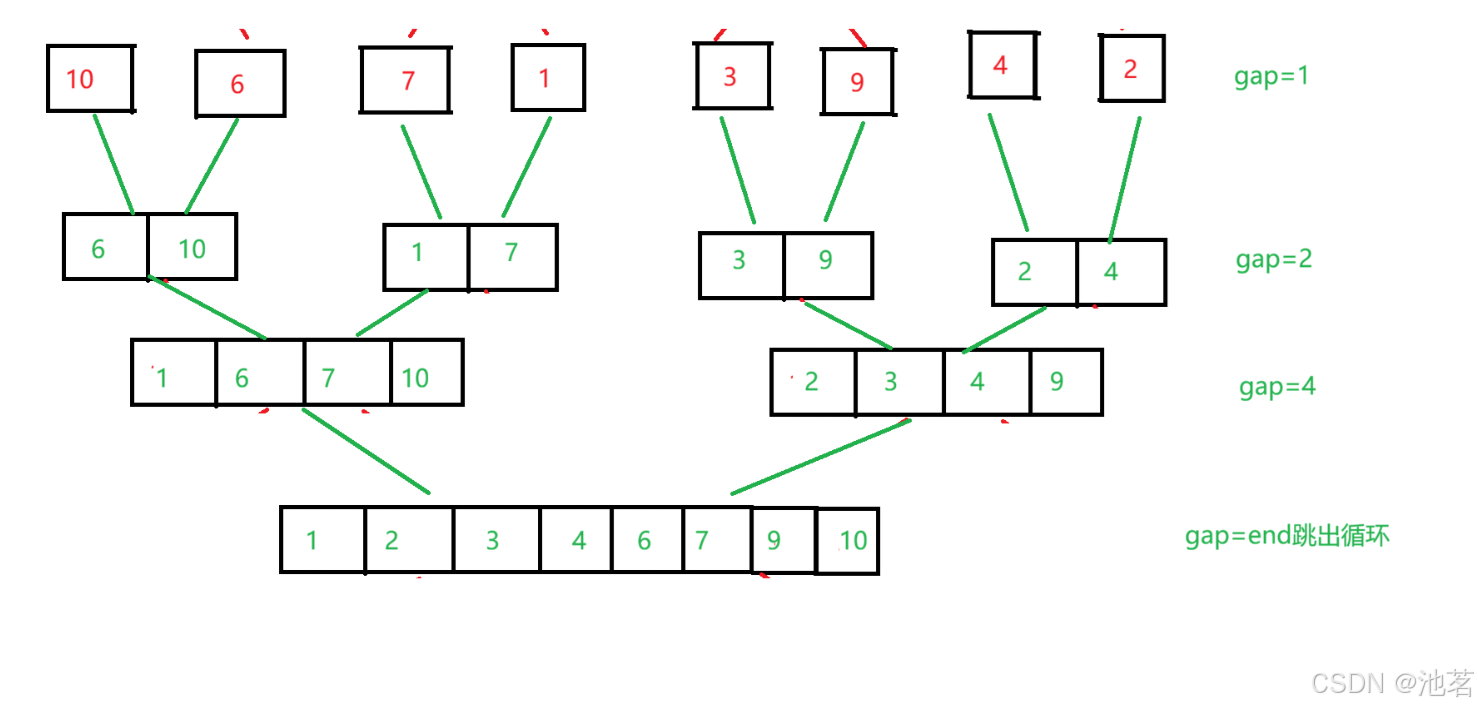
非递归实现的大坑:
就是数据不是整数gap倍,时的归并;
归并会出现访问越界的情况

我们来仔细分析以下的越界情况:

三种越界情况展示>:

在这里我们可以归纳一下越界逻辑
你会发现,end1越界,和end1,begin2越界其实是一种情况,第二区间不存在
都表示后面没有数了不用归并了
// 边界修正 if (end1 >= n|| begin2 >= n) { end1 = n - 1;不归并,直接把尾区间给end1;往下走 break; // 第二区间不存在,跳过 } if (end2 >= n) end2 = n - 1;第二区间还有数继续归并
void _Mergesort2(int* a, int* tmp, int begin, int end) { int n = end - begin + 1; // 总元素个数 int gap = 1; while (gap < n) // 改用 n,更清晰 { for (int i = 0; i < n; i += 2 * gap) { int begin1 = i; int end1 = i + gap - 1; int begin2 = i + gap; int end2 = i + 2 * gap - 1; // 边界修正 if (end1 >= n) end1 = n - 1; if (begin2 >= n) break; // 第二区间不存在,跳过 if (end2 >= n) end2 = n - 1; int left = begin1; // 保存原始左边界 int j = i; // tmp 中的起始索引 while (begin1 <= end1 && begin2 <= end2) { if (a[begin1] < a[begin2]) tmp[j++] = a[begin1++]; else tmp[j++] = a[begin2++]; } while (begin1 <= end1) tmp[j++] = a[begin1++]; while (begin2 <= end2) tmp[j++] = a[begin2++]; // 正确拷贝:从 left 位置开始,长度为 j - left memcpy(a + left, tmp + left, sizeof(int) * (j - left)); } gap *= 2; } } //非递归实现归并 void Mergesort2(int* a, int n) { int* tmp = (int*)malloc(sizeof(int) * n); if (tmp == NULL) { perror("malloc fail"); return; } _Mergesort2(a, tmp, 0, n - 1); free(tmp); tmp = NULL; }
